Text Mining in preußischer Amtspresse
01.10.2020
Einleitung
Denkt man etwas über die Historikerzunft der Zukunft nach, so kommt man nicht darum herum, sich Gedanken über die Vielfalt der Quellen zu machen, die diese Historiker wohl für ihre Forschung untersuchen werden. Rein unter dem Aspekt der Datenmenge wird ein Großteil dieser Quellen mit Sicherheit digital, ja sogar „born-digital“ vorliegen. Tag und Nacht hinterlässt die Menschheit unzählige Texte in Chats, Emails oder Blogposts wie diesem, verkündet die Bandbreite ihrer politischen Meinungen auf Twitter, entsendet Standortdaten auf entlegene Server oder teilt die letzte Mahlzeit tausendfach mit der Welt. Angenommen, auch nur ein Bruchteil dieser Daten überlebt die Reise in unsere vorgestellte Zukunft, so können zukünftige Historiker zwar nicht über Quellenmangel klagen, es ergibt sich jedoch für sie die Gefahr, von der schieren Datenmenge erschlagen zu werden. Benötigt werden Methoden, um sich in absehbarer Zeit und mit absehbarem Aufwand einen guten Überblick über die Daten zu verschaffen. Wir brauchen ein Verfahren, das mithilfe computergestützter Algorithmen erste aussagekräftige Befunde über einen Korpus produziert, den Historiker auf die für eine Fragestellung relevanten Stellen weist und auf diese Weise die effektive menschliche Erforschung des Korpus erst ermöglicht: das Text Mining.
Doch auch der Historiker im Hier und Jetzt kann von Text Mining profitieren, denn durch den Buchdruck wurden bereits in der Frühen Neuzeit Texte in einer Menge produziert, die in einem Menschenleben unmöglich in ihrer Gänze zu erfassen ist. Was es dazu braucht, ist digitalisierter, maschinenlesbarer Text. Wenn sich Technologien wie die Texterkennung OCR (optical character recognition) weiterentwickeln, können bereits vorhandene digitale Scans weiter erschlossen werden; alte Drucke werden zum aufschlussreichen Objekt für Text Mining.
Ein Vorreiter ist dabei das Projekt Digitalisierung der Amtspresse Preußens der Staatsbibliothek zu Berlin, welches „die auflagenstärkste und einflussreichste politische Presse des letzten Drittels im 19. Jahrhundert“ digitalisiert und transkribiert. Für unsere Untersuchung mit Text Mining stellen wir die beiden Zeitungen „Provinzial-Correspondenz“ und „Neueste Mittheilungen“ vergleichend gegenüber. Bei Beiden handelt es sich um Wochenzeitungen, die ländlichen, konservativen Kreisblättern beigelegt wurden. Die Regierungsnähe und Finanzierung der Provinzial-Correspondenz war dabei schon den Zeitgenossen bekannt, was sie als „Sprachrohr der Regierung“ aufwertete. Einen anderen Ansatz verfolgten dagegen die Neuesten Mittheilungen, die geheim von Bismarcks „Reptilienfonds“ finanziert wurden. Unsere beiden Korpora bilden sich aus den zwischen 1863 und 1884 erschienenen 1094 Ausgaben der Provinzial-Correspondenz und den zwischen 1882 und 1894 erschienenen 1327 Ausgaben der Neuesten Mittheilungen; macht insgesamt knapp 2500 Zeitungsausgaben.
Für unsere Zwecke wird dabei jeder Schritt des Text Minings mit der Skriptsprache Python umgesetzt. Zwar existieren bereits nützliche Tools wie Voyant, die ein erstes Text Mining mit ein paar Klicks ermöglichen, doch bietet ein eigenständiger Ansatz folgende Vorteile:
- eine höhere Stabilität bei großen Datenmengen
- die Freiheit, das eigene Programm an die eigenen Bedürfnisse anzupassen
- die Möglichkeit, das Programm ständig zu erweitern
- die Möglichkeit, den Output der Analyse nach Belieben zu gestalten
- die ständige Gewissheit über das Zustandekommen der Daten und der Analyseergebnisse
Im Folgenden wird der Prozess des Text Minings mit Python Schritt für Schritt durchgeführt und erläutert. Grundlagen in Python werden vorausgesetzt. Der komplette Code kann über GitHub heruntergeladen werden, es müssen lediglich die Pfadangaben angepasst werden.
Web Scraping
Bevor wir uns analytisch mit den Daten auseinandersetzen können, müssen wir diese zunächst einmal zusammentragen. Da es sich um große Datenmengen handelt, wollen wir uns jedoch nicht einzeln durch die Downloads klicken, sondern automatisieren den Vorgang mithilfe der API der Berliner Staatsbibliothek und natürlich Python. Die URLs, an die wir unsere Anfragen stellen, sind dabei folgendermaßen aufgebaut:
wobei „SNP9838247“ die Identifikationsnummer der Zeitung darstellt, in diesem Fall die Provinzial-Correspondenz, und „18630701“ das Datum der Ausgabe meint, den 01.07.1863. Das Ziel unseres Skripts muss es sein, jede Ausgabe der Zeitungen durch automatische Anfragen herunterzuladen. Benötigt werden hierfür folgende Module:
requests, um HTTP-Anfragen an die Staatsbibliothek zu senden, datetime, um eine Zeitspanne zu errechnen, und time, um den Server nicht mit zu vielen Anfragen zu belasten. Bevor wir die ersten Anfragen stellen, müssen wir die nötigen Variablen vorbereiten:
Dafür legen wir die jeweiligen ID-Nummern der Zeitungen fest und können mit Hilfe des Datetime-Moduls einen Start- bzw. Endpunkt von der ersten bis zur letzten Ausgabe bestimmen. Diese Angaben werden später automatisch in den konstanten String root_url eingefügt und bilden so unsere individuellen URLs für die Anfragen. Dank des Abschnitts „Verallgemeinerung“ können wir bei Bedarf die Zeitung durch eine einfache Modifikation des Strings paper wechseln. Abschließend errechnen wir die Zeitspanne zwischen der ersten und letzten Ausgabe, um die Dauer unserer folgenden For-Schleife festzulegen.
Der Code für die eigentlichen Anfragen ist dabei recht überschaubar:
Die Schleife durchläuft die vorher definierte Zeitspanne, es werden also so viele Anfragen gestellt, wie sich Tage zwischen dem Anfangs- und dem Enddatum befinden. Da wir für unsere Anfrage ein Datum benötigen, bestimmen wir dies durch die Addition des Anfangsdatums und eines Zeitdeltas abhängig vom aktuellen Schleifendurchlauf. Da die API ein YYYYMMDD-Format verlangt, wandeln wir das Datum entsprechend um und fügen es zusammen mit der Zeitungs-ID in die Root-URL, so dass eine wohlgeformte URL entsteht. Nun können wir endlich mit requests.get(url) eine Anfrage schicken und das Ergebnis in einer Variable speichern. Da die Zeitungen jedoch nicht täglich, sondern wöchentlich erschienen sind, werden wir für die meisten Anfragen nicht die gewünschten Dateien erhalten. Dies können wir einfach mit Hilfe der raise_for_status()-Funktion überprüfen. Sollte die Überprüfung positiv sein, erstellen wir eine XML-Datei, benennen sie nach dem Datum der Ausgabe und beschreiben sie mit dem durch die Anfrage erhaltenen Inhalt. Wichtig ist dabei, dass dem Attribut encoding der String „utf-8“ übergeben wird, da es sonst zu Problemen mit Umlauten kommen kann. Zu guter Letzt gehört es zum guten Ton, nicht direkt zum nächsten Schleifendurchlauf überzugehen und so die nächste Anfrage zu senden. Mit time.sleep(x) pausiert das Skript x Sekunden und verringert auf diese Weise die Belastung des Servers und die Gefahr, blockiert zu werden.
Bei Erfolg haben wir nun 1094 + 1327 XML-Dateien lokal gespeichert.
Aufteilen in Artikel
Um bei der Untersuchung bis auf Artikelebene vordringen zu können, müssen die Zeitungsausgaben in ihre einzelnen Artikel aufgeteilt werden, die als separate Textdateien gespeichert werden. Bei den beiden Zeitungen besteht der Vorteil, dass sie bereits mit XML ausgezeichnet sind, also bereits nutzbare Metainformationen über die Dokumentenstruktur vorliegen. Leider sind in der hier vorliegende XML-Auszeichnung die Artikel nicht (etwa durch ein eigenes Element) eindeutig von sonstigen Textabschnitten unterscheidbar, so dass wir einen etwas komplizierten Ansatz wählen müssen.
Wirft man stichprobenartig einen genaueren Blick in ein paar unserer XML-Dateien, wird ersichtlich, dass Artikel entweder nach den Elementen <untertitel> oder <hr/> beginnen. Das Untertitel-Element bezeichnet dabei immer eine Überschrift. Unterhalb dieser Überschriften können sich allerdings mehrere voneinander zu trennende Artikel befinden, so dass zusätzlich nach <hr /> getrennt werden muss. Diese beiden Beobachtungen bilden die Grundlage für die folgende Aufteilung nach Artikeln.
Wir benötigen das OS-Modul und unsere Variable für die Umstellung der beiden Zeitungen. Außerdem definieren wir schon einmal eine Funktion stripper, die den Anfang und das Ende von Listenelementen von Leerzeichen und Umbrüchen befreit. Diese Funktion werden wir noch in diesem und im nächsten Kapitel benötigen.
Will man selbst etwas an den Stellschrauben der Artikelaufteilung drehen, ist es ratsam, vor jeder Ausführung des Skriptes den Output der vorangegangenen Ausführung zu löschen, um eine Durchmischung von alten und neuen Daten zu vermeiden. Um dies nicht jedes Mal manuell machen zu müssen, setzen wir den entsprechenden Python-Code an den Anfang unseres Splitters:
Der Teil des Skriptes, der für die eigentliche Aufteilung in Artikel zuständig ist, sieht wie folgt aus:
Wir gehen in einer Schleife jedes XML-Dokument durch, das wir im letzten Kapitel heruntergeladen haben und speichern den Inhalt in data. Als erstes wird dann der Teil nach dem Element <fusszeile> abgetrennt, da sich dieser in jeder Ausgabe wiederholt. In Zeile 7 erlangen wir bereits eine grobe Einteilung in Artikel, indem wir nach <untertitel> trennen und gleichzeitig das erste Element der Liste beseitigen, bei dem es sich um die Kopfzeile handelt. In der Kopfzeile befinden sich lediglich Angaben über die Ausgabe, über die wir durch Metadaten bereits verfügen. Es folgt die genauere Aufteilung nach dem Element <hr/>. Da diese zweite Aufteilung eine Typdurchmischung von sowohl Strings als auch Listen in der Liste data produziert, müssen die Strings der verschachtelten Listen wieder auf eine Ebene mit den Strings in data gebracht werden, was in den Zeilen 14-22 geschieht. Die Aufteilung führt außerdem evtl. zu Leerzeichen und Umbrüchen an ungewünschten Stellen, so dass wir unsere vorher definierte Stripper-Funktion ausführen. In einem weiteren Schritt extrahieren wir „Überüberschriften“. Das sind Überschriften, die über anderen Überschriften stehen; sie enden stets mit dem schließenden Tag </untertitel>. Da wir sie noch für das spätere Sammeln von Metadaten gebrauchen können, speichern wir sie in einer Variable, bevor wir sie aus unseren Artikeln löschen. Um evtl. sehr kurze oder gar leere Artikel zu verhindern, löschen wir in einem letzten Schritt noch alle Artikel, die weniger als drei Wörter besitzen.
Abschließend werden die Artikel separat als TXT-Datei gespeichert und eindeutig benannt. Bei unserem Ansatz der Artikelaufteilung entstehen auf diese Weise 8243 Dateien für die Provinzial-Correspondenz und 17900 Dateien für die Neuesten Mittheilungen.
Säuberung des Textes
Um den Text zu säubern, so dass nur der Text übrigbleibt, den wir untersuchen wollen, müssen wir ihn von seinen XML-Tags befreien. Bei Python bieten sich mehrere Ansätze, mit XML umzugehen. Einer von ihnen wäre die Nutzung des Moduls Beautiful Soup, das die Arbeit mit XML- und HTML-Dokumenten ermöglicht. Da wir allerdings nicht mehr machen wollen, als unseren Text von Tags zu befreien, greifen wir auf reguläre Ausdrücke zurück.
Zu diesem Zweck erstellen wir kein neues Skript, sondern modifizieren den Splitter. Die Daten werden dabei gesäubert, bevor sie als separate Text-Dateien gespeichert werden. Wir müssen unser Skript anschließend also erneut ausführen. Zu Beginn des Skriptes fügen wir folgende Zeilen hinzu:
Das Modul re wird für reguläre Ausdrücke benötigt. Außerdem definieren wir für die Säuberung einen xmlDeleter, da wir diesen im späteren Metadatensammler mehrmals benutzen müssen. Dieser durchläuft unsere Artikelliste und ersetzt zunächst alle Elemente <br/> durch ein Leerzeichen, da sonst Wörter zusammenrücken würden, die nicht zusammen gehören. Anschließend werden alle XML-Tags erkannt und durch nichts ersetzt. Ein XML-Tag wird hier als etwas definiert, das durch eine spitze Klammer eröffnet und geschlossen wird, einen Schrägstrich als zweiten oder vorletzten Charakter haben kann und sonst aus Buchstaben besteht. Rein theoretisch kann ein XML-Element auch u.a. aus Zahlen bestehen (oder aus Fragezeichen für Verarbeitungsanweisungen), doch das ist in unseren Dokumenten nicht der Fall.
Die Funktion muss dann nur noch an der richtigen Stelle ausgeführt werden. Hier wird sie eingefügt, sobald keine XML-Tags mehr benötigt werden, also nach der Löschung der Überüberschriften.
Erfassen von Metadaten
Der Schritt der Metadatenerfassung ist insoweit ein entscheidender, dass die Art und Qualität der hier gesammelten Metadaten bestimmen, welche Untersuchungen wir später mit unseren Daten überhaupt durchführen können. Sie verändern die uns zur Verfügung stehenden Blickwinkel auf unsere Korpora. Aus diesem Grund wird dieser Schritt im Laufe einer Untersuchung auch häufig mehr als einmal durchgeführt; mit neuen Fragestellungen ändern sich auch die Ansprüche an die Metadaten.
Das Sammeln der Metadaten erfolgt ebenfalls parallel zur Aufteilung in einzelne Artikel. Wir erstellen also kein neues Skript, sondern modifizieren unser bestehendes. Da die Metadaten als CSV-Datei gespeichert werden sollen, benötigen wir dafür das entsprechende Modul:
Außerhalb unserer For-Schleife können wir bereits bestimmen, was unabhängig von den Ausgaben konstant bleibt.
Das ist der Aufbau einer Zeile in der CSV-Datei, die wir für jeden Artikel anhängen wollen, in Form eines Dictionarys. Hier legen wir fest, welche Metadaten wir eigentlich erfassen wollen. Das Topic-Modeling-Tool, mit dem wir später arbeiten werden, verlangt, dass an erster Stelle in den Metadaten der Dateiname erfasst wird, auf den sich die jeweilige Zeile bezieht. Der Zeitungsname kann als Konstante hier bereits übergeben werden.
Außerdem können wir an dieser Stelle die CSV-Datei erstellen und diese bereits mit einer Überschriftszeile, einem Header, versorgen, der sich aus den Keys unseres Dictionarys bildet.
Nun muss darauf geachtet werden, dass die jeweiligen Metadaten an den richtigen Stellen im Skript erfasst werden. Gleich zu Beginn in unserer For-Schleife können wir etwa verschiedene Datumsangaben speichern, die innerhalb einer Ausgabe natürlich gleich bleiben. Außerdem definieren wir unseren zu speichernden csvContent als leere Liste, da sich ihr Inhalt bei jeder neuen Ausgabe zurücksetzen soll.
Es folgt die Speicherung der Überschriften für jeden Artikel. Da die Überschriften immer nur als Teil des ersten Artikels unter dieser Überschrift stehen, müssen sie an die darauffolgenden Artikel übertragen werden. Dies geschieht zwischen der Löschung der Überüberschriften und der Säuberung der Daten.
Wie bereits mit data geschehen, werden an dieser Stelle außerdem die Überschriften und Überüberschriften von ungewollten Leerzeichen und XML-Tags gesäubert.
Aufgrund des nicht optimalen XML würden viele der in den Metadaten erfassten Überschriften lediglich aus römischen Zahlen bestehen. Da diese rein durch das XML nicht von „echten" Überschriften zu unterscheiden sind, müssen wir uns mit Hilfe von Python davon befreien:
Nach der Löschung der zu kurzen Artikel können schließlich die letzten Metadaten erfasst werden:
Dafür dringen wir bis auf Artikelebene vor und erfassen z.B. die Wörterzahl der Artikel. Außerdem hängen wir die einzelnen csvRows, die jeweils einen Artikel abbilden, an csvContent an, das die csvRows einer Ausgabe umfassen soll. Zuletzt können die in einer Ausgabe gesammelten Metadaten an unsere bereits bestehende CSV-Datei angehängt werden. Wichtig ist dabei, dass dem Attribut mode der Wert „a“ übergeben wird, damit es nicht zu ungewollten Überschreibungen kommt.
Insgesamt sieht unser Skript, das gleichzeitig in Artikel aufteilt, den Text säubert und Metadaten sammelt, folgendermaßen aus:
Erstes Explorieren der Korpora
Mit den gesammelten Metadaten können wir nun endlich mit der quantitativen Exploration beginnen. Auch diesen Schritt können wir rein in Python umsetzen, so dass wir ein neues Skript erstellen und folgende Module importieren:
Pandas wird uns bei der Analyse und richtigen Strukturierung unserer Daten gute Dienste erweisen, während Matplotlib benötigt wird, um aus unseren Daten aussagekräftige Grafiken, etwa in Gestalt von Graphen, zu erzeugen. Dann können wir beginnen, indem wir unsere Metadatendateien als Dataframes in Pandas laden:
Als erster Schritt bietet es sich an, unsere Daten auf evtl. Fehler zu untersuchen, damit unsere Analyse auf sicherem Fundament entstehen kann. Dafür sind besonders die Methoden df_PC.head() bzw. df_PC.tail() geeignet, mit denen wir uns die ersten bzw. letzten Einträge unserer Daten anzeigen lassen können. Fehler im gesamten Corpus lassen sich gut mit df_PC.info() erkennen. Hier sollte darauf geachtet werden, dass die Datentypen den gewünschten entsprechen und der „Non-Null Count" möglichst in allen Fällen der Zahl der Gesamteinträge entspricht, andernfalls könnte das auf Lücken in der Metadatenerfassung hindeuten.
Mit df_PC.describe() lassen sich erste statistische Aussagen über einen Korpus treffen. Neben Durschnittswerten und Standardabweichungen ist diese Methode sehr nützlich, um Extrema aufzudecken. Wir stellen etwa fest, dass der längste Artikel in der Provinzial-Correspondenz einen Umfang von 14347 Wörtern hat und dass es sogar eine Ausgabe mit nur einem einzigen Artikel gibt. Diesen Hinweisen können wir nachgehen, indem wir uns mit df_PC.sort_values(by="Woerteranzahl_Artikel") die Einträge mit den längsten und kürzesten Artikeln anzeigen lassen. Die längsten vier Artikel in der Provinzial-Correspondenz sind alles abgedruckte Reden des Reichskanzlers Bismarck, der fünftlängste ist ebenfalls eine Rede, nämlich von Innenminister von Puttkamer. Im Gegensatz lassen sich diese extremen Längen in den Neuesten Mittheilungen nicht finden, hier umfassen die längsten fünf Artikel 3633 bis 4620 Wörter. Bei dreien handelt es sich auch hierbei um Ausschnitte aus Reden von Regierungsmitgliedern.
Wir verfolgen die Spur der Artikellänge zunächst weiter und überprüfen, ob sich eine Systematik feststellen lässt. Dafür nutzen wir Pandas und Matplotlib, um uns mit zwei Histogrammen die Häufigkeitsverteilung der Artikellängen zu visualisieren:
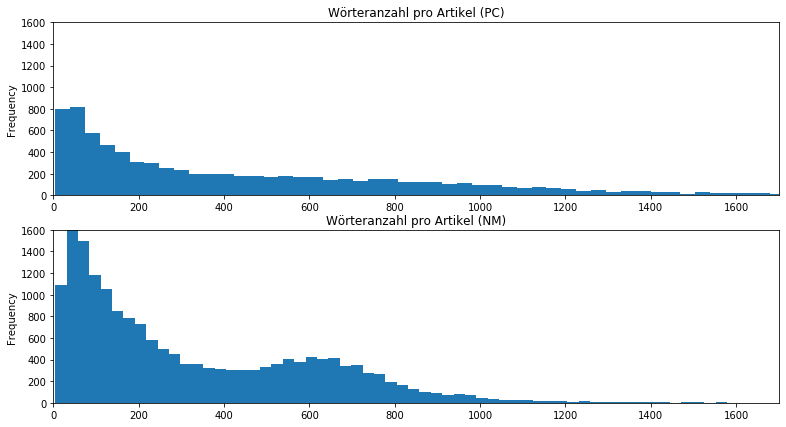
Es ist auffällig, dass die Neuesten Mittheilungen eine sehr hohe Häufigkeit bei sehr kurzen Artikeln unter 200 Wörtern aufweisen und die Häufigkeit bei Artikeln mit über 800 Wörter stark abnimmt. Im Gegensatz dazu lässt sich zwar auch eine vermehrte Häufigkeit der kurzen Artikel in der Provinzial-Correspondenz feststellen, doch verteilen sich die Zahlen deutlich gleichmäßiger auch auf die längeren Artikel. Das lässt sich besser beobachten, wenn wir unseren Fokus auf die längeren Artikel setzen, indem wir in unserem Skript die Grenzen der x- und y-Achsen unserer Histogramme entsprechend anpassen:
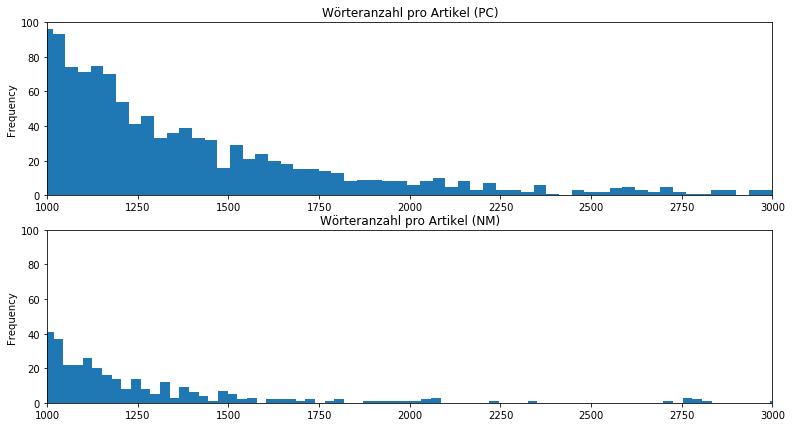
Es wird deutlich, dass die Neuesten Mittheilungen nur geringfügige Mengen an längeren Artikeln aufweisen können. Sie scheinen von Kurznachrichten dominiert zu sein. Demgegenüber sind die Artikellängen der Provinzial-Correspondenz deutlich breiter aufgestellt, es findet sich eine höhere Diversität an Artikellängen. Schon jetzt ist festzuhalten, dass mit der Einführung der Neuesten Mittheilungen nicht nur die Wege der Finanzierung, sondern auch die mediale Strategie geändert wurde, indem vermehrt auf sehr kurze Artikel gesetzt wurde. Betrachtet man die Entwicklung der durchschnittlichen Artikellängen chronologisch, lässt sich diese Beobachtung bestätigen. Dafür legen wir mit Pandas unsere Daten nach Jahren zusammen und bilden in diesen den Durchschnitt. Dann visualisieren wir uns die Ergebnisse auf einem Liniendiagramm:
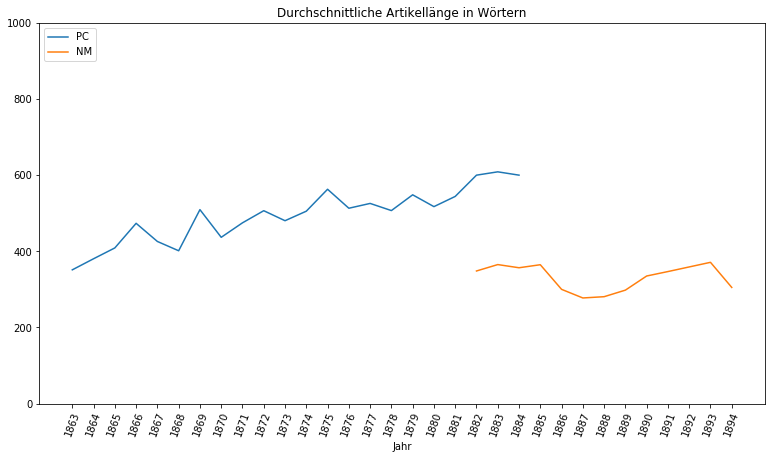
Artikel der Provinzial-Correspondenz sind mit Schwankungen insgesamt länger geworden. Die Zeitung begann 1863 mit einer durchschnittlichen Artikellänge von 351 Wörtern und endete mit einer Zahl von durchschnittlich 600. Die Neuesten Mittheilungen setzten dagegen nicht bloß 1882 mit 348 Wörtern deutlich niedriger an die Provinzial-Correspondenz an, sondern verringerten im Laufe ihres Bestehens sogar ihre Artikellängen auf durchschnittlich bis zu 280 Wörter in den Jahren von 1886-1889.
Deutliche Unterschiede sind auch bei der Anzahl der Artikel pro Ausgabe feststellbar. Dafür legen wir unsere Daten diesmal nach einzelnen Ausgaben zusammen (also „Jahr_Monat_Tag“) und bilden wieder den Durchschnitt. Dann visualisieren wir die Daten in zwei Säulendiagrammen:
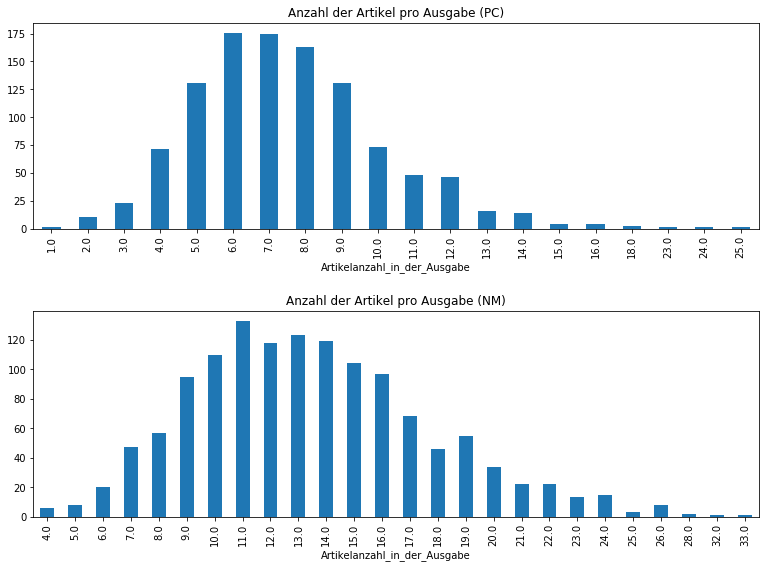
Die Artikelanzahl der Provinzial-Correspondenz häuft sich im Gegensatz zu den Neuesten Mittheilungen in einem deutlich niedrigeren Bereich, etwa vier bis zehn Artikel pro Ausgabe. Im Vergleich häuft sich die Artikelanzahl der Neuesten Mittheilungen bei etwa acht bis neunzehn Artikel und kann selbst im Zwanzigerbereich noch relativ hohe Zahlen nachweisen. Die Struktur der Neuesten Mittheilungen besteht also nicht nur aus sehr kurzen Artikeln, sondern eben auch aus sehr vielen von diesen. In chronologischer Ansicht lassen sich bei den Neuesten Mittheilungen dabei erhebliche Schwankungen nachweisen:
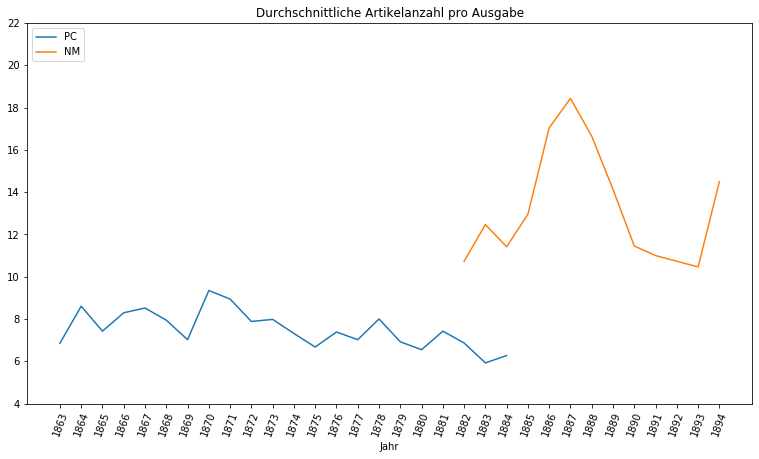
Während sich die durchschnittliche Artikelanzahl der Provinzial-Correspondenz relativ konstant verhielt, stieg die der Neuesten Mittheilungen zwischen 1884 und 1887 von 11 auf 18, sank dann jedoch auf 10 ab, nur um im letzten Jahr wieder auf 14 zu klettern. Interessant ist in diesem Zusammenhang auch der Blick auf die Entwicklung der durchschnittlichen Ausgabenlänge im Laufe der Jahre:
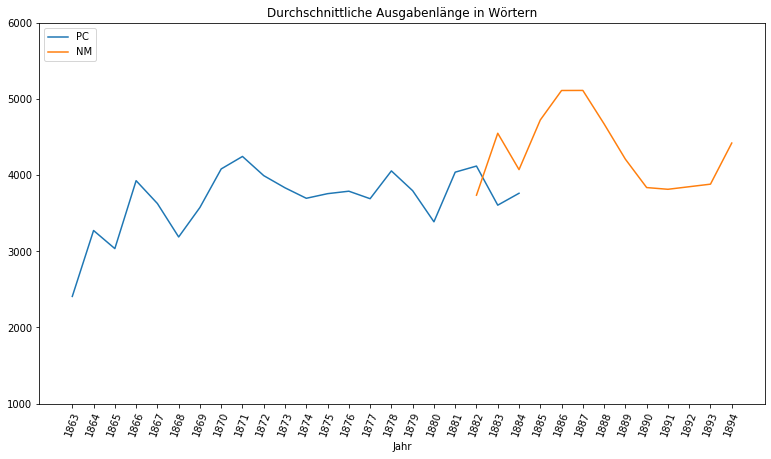
Nicht nur ist auffällig, dass die Ausgabenlänge der Provinzial-Correspondenz im Laufe ihres Bestehens deutlich angestiegen ist, nämlich um ~1400 Wörter, und dass beide Zeitungen zum Zeitpunkt der Ablösung 1884 eine vergleichbare Länge von rund 3700 Wörtern hatten, sondern auch, dass die Ausgabenlänge stark mit der Artikelanzahl korreliert. Zwischen 1884 und 1887 wurden die Ausgaben der Neuesten Mittheilungen also deutlich länger. Anstatt jedoch die (relativ kurzen) Artikel zu verlängern (sie wurden sogar kürzer), wurde lediglich ihre Anzahl deutlich erhöht.
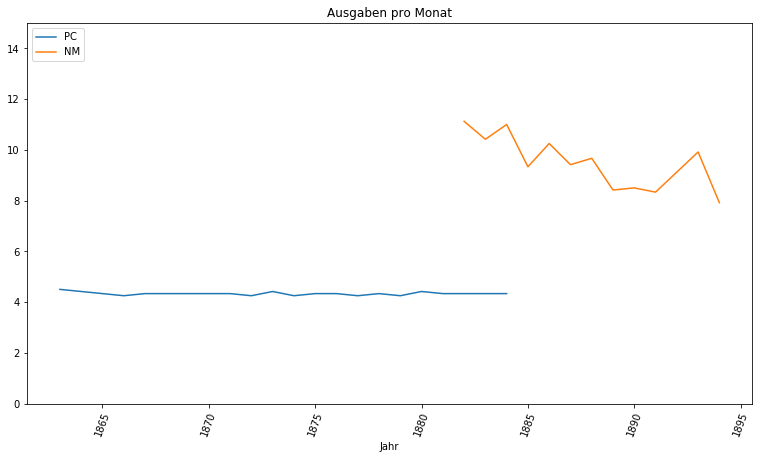
Auch sind die Neuesten Mittheilungen in einer deutlich höheren Frequenz erschienen. Wo die Provinzial-Correspondenz als klassische Wochenzeitung mit vier Ausgaben pro Monat beschrieben werden kann, ist dies bei den Neuesten Mittheilungen mit einer neuen Ausgabe alle drei bis vier Tage nicht der Fall:
Zu guter Letzt lohnt sich ein Blick auf die Artikelüberschriften, die wir ja auch in unserem Metadatensammler erfasst haben. Dafür lassen wir uns bei beiden Zeitungen die fünf häufigsten Überschriften anzeigen. Um eine Überschrift nur höchstens einmal pro Ausgabe zu zählen, legen wir dafür zunächste unsere Daten nach sowohl den einzelnen Ausgaben als auch den Überschriften zusammen. Anschließend zählen wir die zusammengelegten einzigartigen Überschriften und lassen uns das Ergebnis als geordnete Tabelle anzeigen:
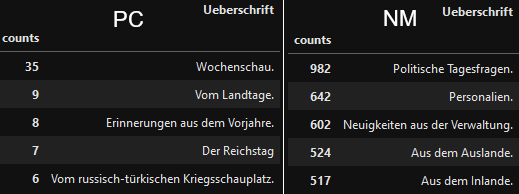
Der Kontrast zwischen den beiden Zeitungen ist gewaltig. Die häufigste Überschrift der Provinzial-Correspondenz, die Wochenschau, ist tatsächlich nur in 35 der 1094 erschienenen Ausgaben der Zeitung vorhanden. Die nächsten vier häufigsten Überschriften liegen sogar im einstelligen Bereich. Im Gegensatz dazu ist die fünfthäufigste Überschrift der Neuesten Mittheilungen in 517 der 1327 Ausgaben vertreten und die „Politischen Tagesfragen“ sogar in 982, das sind 74% aller Ausgaben. Noch deutlicher wird der Kontrast, wenn wir uns das Vorkommen dieser Überschriften im Laufe der Jahre graphisch anzeigen lassen:
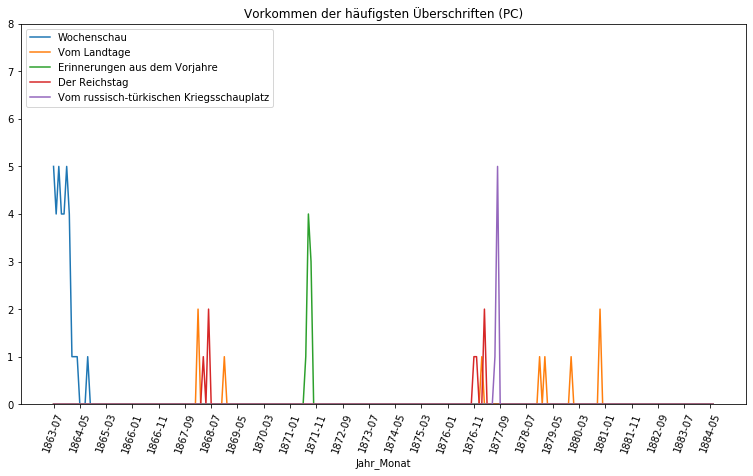
Erkennbar handelt es sich bei den Überschriften der Provinzial-Correspondenz um „Eintagsfliegen“, die höchsten wenige Monate oder Wochen in den Ausgaben zu finden sind. Auch die Wochenschau als häufigste Überschrift stellt sich lediglich als Phänomen der Anfangsphase der Zeitung heraus, die nach ein paar Monate eingestampft wurde und danach nie wieder feststellbar ist. Eine Ausnahme bildet da der Bericht „Vom Landtage“, der über die Jahre immer mal wieder auftaucht. Von Regelmäßigkeit kann jedoch auch hier nicht gesprochen werden.
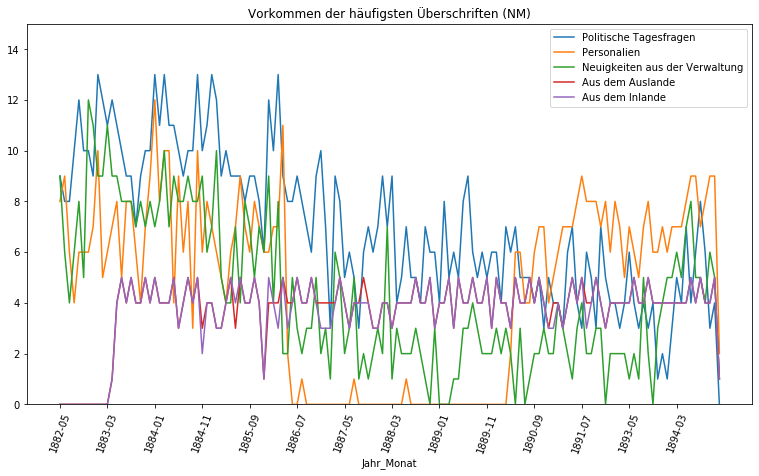
Ganz anders die Neuesten Mittheilungen. Hier erweisen sich die fünf häufigsten Überschriften im Laufe der Jahre als sehr konstant. Lediglich die „Personalien“ scheinen zwischen Juli 1886 und Anfang 1890 nicht genutzt worden zu sein. Als sehr regelmäßig stellt sich der Bericht „Aus dem Inlande“ dar, der zunächst nicht Teil der Neuesten Mittheilungen war, dann jedoch relativ konstant in vier Ausgaben im Monat anzutreffen ist.
Durch eine erste Exploration mit Text Mining lässt sich bereits ohne einen Blick in die tatsächlichen Zeitungsausgaben zu werfen eine neue Medienstrategie in der Preußischer Amtspresse mit der Einführung der Neuesten Mittheilungen 1882 erkennen. Von Anfang an setzten die Neuesten Mittheilungen auf eine höhere Frequenz der Ausgaben und wichen so vom klassischen Konzept der Wochenzeitungen ab. Gleichzeitig wurden die Ausgaben insgesamt länger (ein Trend, der schon über die Jahre bei der Provinzial-Correspondenz zu beobachten war); die Neuesten Mittheilungen produzierten auf diese Weise pro Monat deutlich mehr Text. Doch auch der innere Aufbau der beiden Zeitungen lässt sich gegenüberstellen. Während die Provinzial-Correspondenz auch vor längeren Artikeln nicht zurückschreckte, setzten die Neuesten Mittheilungen verstärkt auf sehr viele und besonders kurze Artikel. Ein komplett neuer Ansatz ist bei der Strukturierung durch regelmäßige Überschriften in den Neuesten Mittheilungen festzustellen: Zum ersten Mal finden sich Überschriften, die beinahe die gesamte Lebenszeit der Zeitung Bestand haben und in hoher Regelmäßigkeit in den Ausgaben vorkommen. Die Überschriften und somit auch die thematische Zusammensetzung der Neuesten Mittheilungen waren für den Leser deutlich absehbarer.
Topic Modeling
Mit Hilfe von Topic Modeling gewinnen wir Einblicke in die thematische Zusammensetzung eines großen Textkorpus, indem ein Algorithmus semantisch nahestehende Wörter erkennt und sie in einzelne Topics ordnet. Dafür nutzen wir die GUI-Version des MALLET Topic Modeling Tools. Im Tool verweisen wir mit dem Input Directory auf die aufgeteilten Artikel im TXT-Format. In den weiteren Einstellungen übergeben wir unsere Metadatendatei und zudem eine deutsche Stopwordliste, die wenig aussagekräftige Wörter automatisch ignoriert. Im Internet lassen sich viele Stopwordlisten frei herunterladen. Die Parameter Topicanzahl, Wörteranzahl pro Topic und Anzahl der Durchläufe müssen je nach Korpus angepasst werden. Eine zu hohe Topicanzahl etwa würde Topics auseinanderreißen, die eigentlich zusammengehören, während eine zu niedrige Anzahl Topics mischen würde, die eigentlich getrennt betrachtet werden müssten. Mit unseren Korpora bin ich mit 20 Topics, 15 Wörtern pro Topic und 1000 Durchläufen zu guten Ergebnissen gekommen. Das Ergebnis des Topic Modelings können wir genau so mit Pandas und Matplotlib bearbeiten wie im vorherigen Kapitel. Dafür laden wir als Dataframe jedoch nicht unsere alte Metadatendatei, sondern die durch das Topic Modeling erweiterte „topics-metadata.csv“ im Ordner „output_csv“.
Zunächst ist es ratsam, sich einen generellen Überblick über die thematische Zusammensetzung des Korpus zu machen. Um herauszufinden, welche Themen insgesamt besonders dominant sind, bilden wir pro Topic die Summe aller Zeilen und ordnen das Ergebnis absteigend:
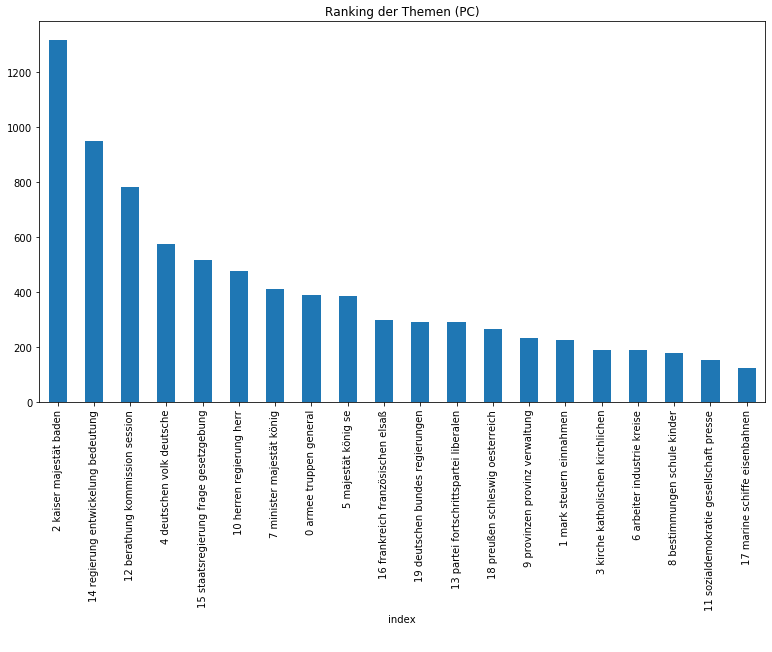
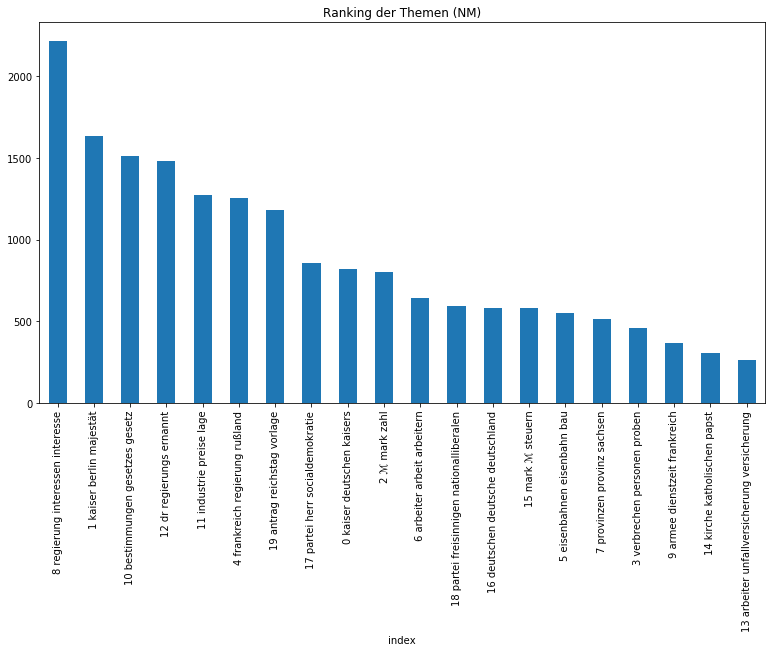
Beide Zeitungen sind sichtbar zurecht als Amtspresse einzuordnen, so dominieren Themen über die Monarchie, die Regierung, Gesetze, Verwaltung, aber auch wirtschaftliche und außenpolitische Themen. Auffällig ist, dass das monarchische Thema in den Neuesten Mittheilungen vom Thema „Regierung“ auf den zweiten Platz verwiesen wird, was sicherlich mit der Zeit der Kaiserreichsgründung zusammenhängt, die nur von der Provinzial-Correspondenz abgedeckt wurde und entsprechend eine höhe Gewichtung besaß. Von den Zeitungen in ihrer Gesamtheit können wir uns im nächsten Schritt auf die Ebene der Artikel begeben und etwa herausfinden, wie sich die Artikeltypen, die in den Neuesten Mittheilungen regelmäßig vorkommen, thematisch voneinander unterscheiden:
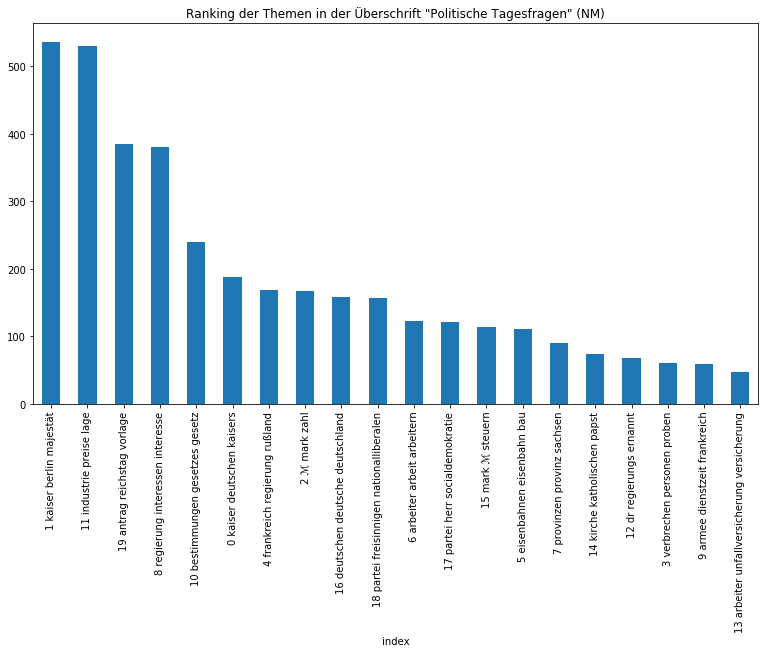
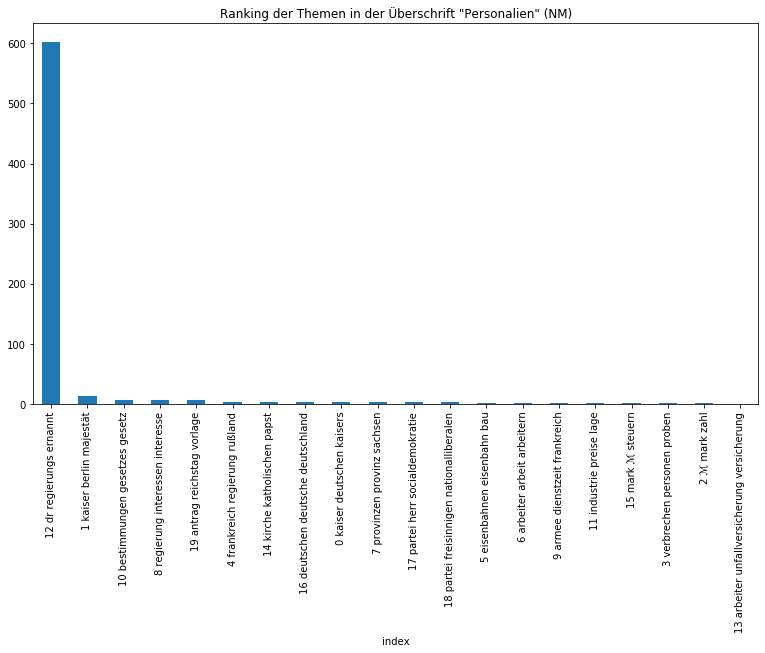
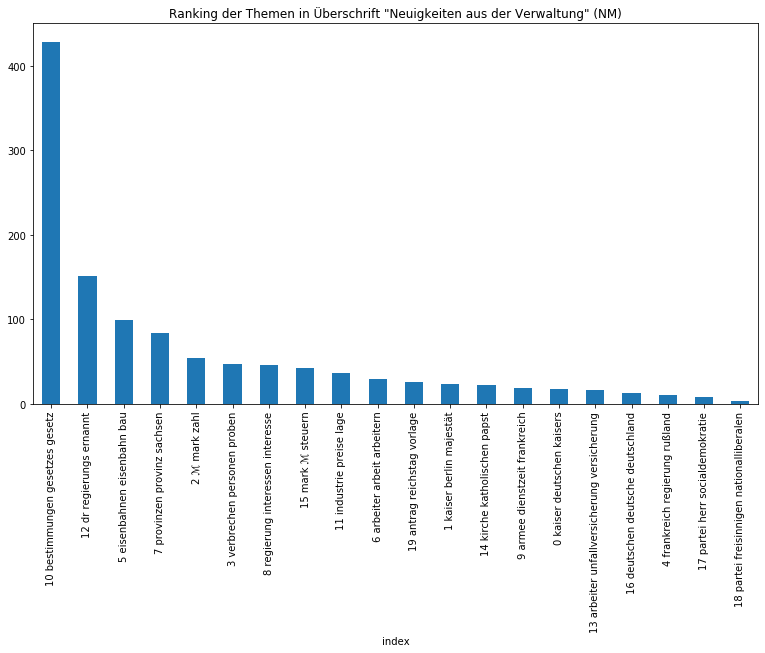
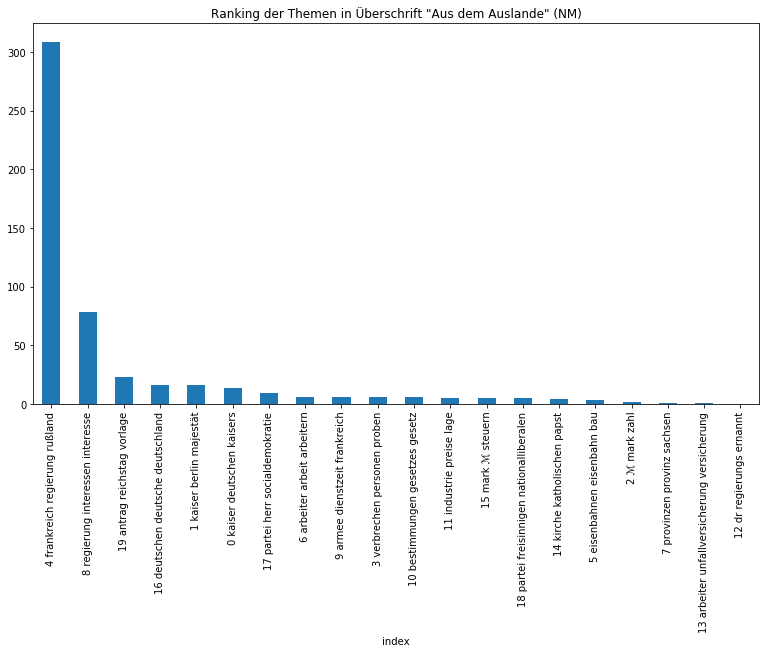
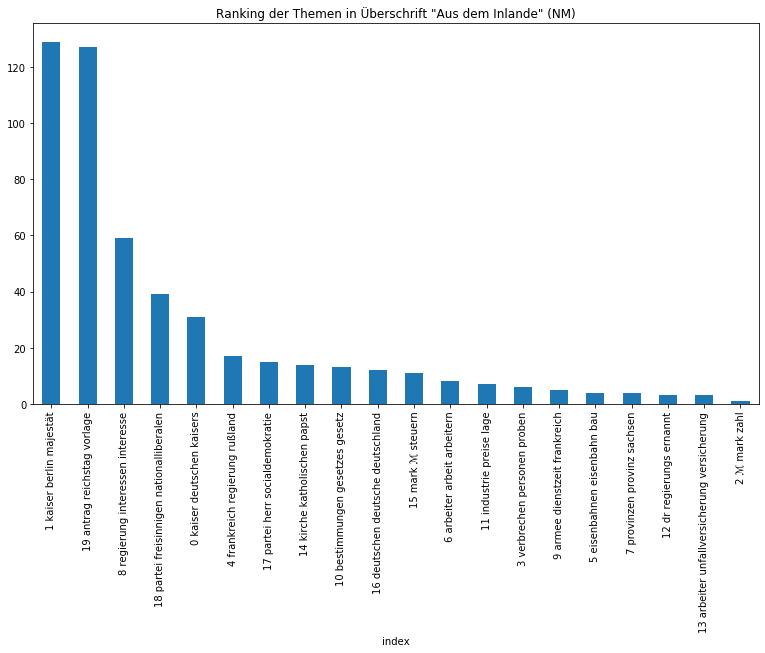
Auch wenn die Ergebnisse nicht immer überraschen, eine gute Überschrift gibt schließlich bereits einen Ausblick auf die darauffolgende Thematik, eignet sich diese Methode nicht nur, um Gewissheit zu erlangen, sondern gerade, um auf überraschende Zusammensetzungen aufmerksam gemacht zu werden und sich nicht vorschnell von der Überschrift leiten zu lassen.
Bildet man in den einzelnen Jahren den Durchschnitt der Themenwerte, kann man diese chronologisch visualisieren und auf diese Weise die Reaktion der Zeitungen auf historische Ereignisse und Entwicklungen beobachten:
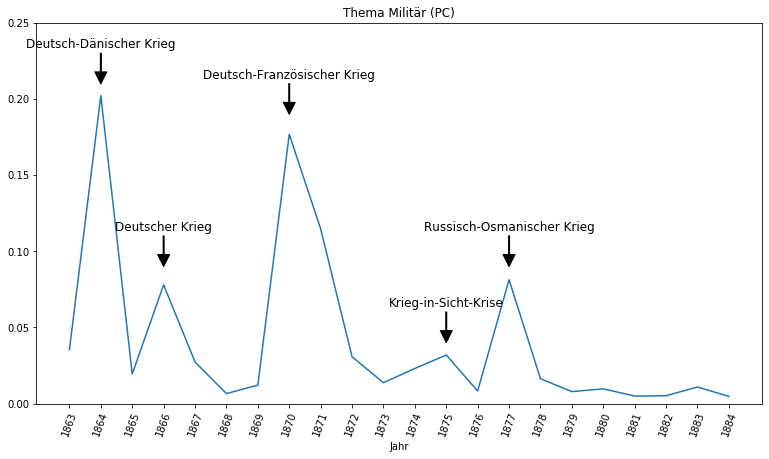
Anhand des Topics Militär lassen sich anschaulich die Kriege und militärischen Krisen der Zeit darstellen. Die beiden höchsten Ausschläge lösten der Deutsch-Dänische und der Deutsch-Französische Krieg aus, sogar die Krieg-in-Sicht-Krise ist erkennbar. Vergleicht man die Ausschläge mit denen anderer Themen auf der gleichen Skala (siehe folgende), wird deutlich, wie dominant das Militärthema in den Ausgaben dieser Jahre gewesen sein muss.
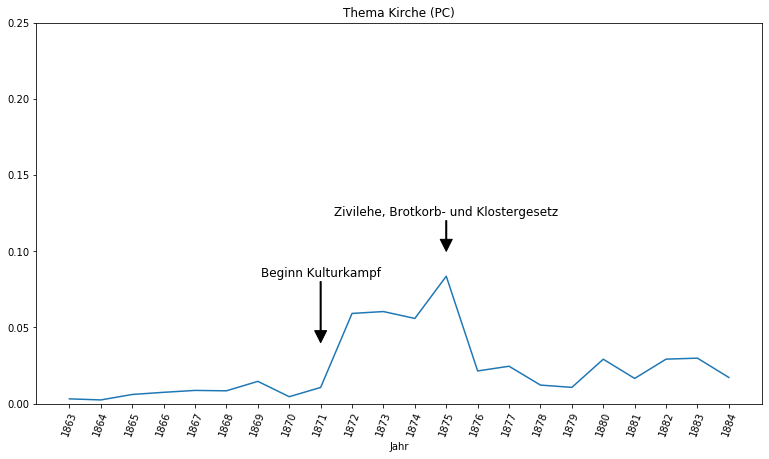
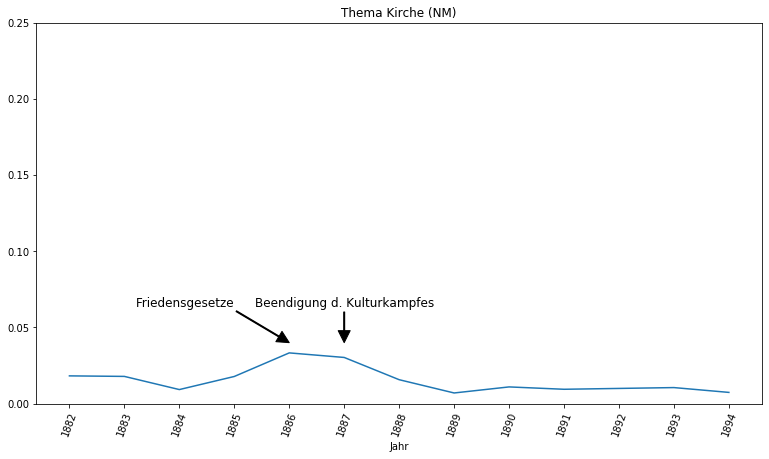
Auch der Verlauf des Kulturkampfes ist in beiden Zeitungen nachzuvollziehen. Das Thema Kirche gewinnt in der Provinzial-Correspondenz ab 1871 mit Beginn des Kulturkampfes deutlich an Relevanz und teilt sich 1875 mit der Einführung der Zivilehe und dem Brotkorbgesetz und Klostergesetz seinen Höhepunkt mit dem Kulturkampf. In den Neuesten Mittheilungen gewinnt das Thema erneut mit schrittweiser Beilegung des Kulturkampfes an Relevanz, auch wenn das Thema nicht mehr den Stellenwert erreicht, den es zur Anfangsphase des Kulturkampfes genossen hat.
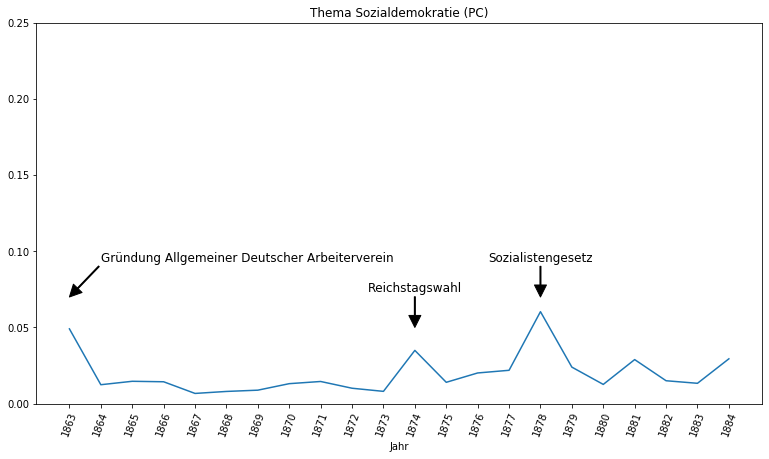
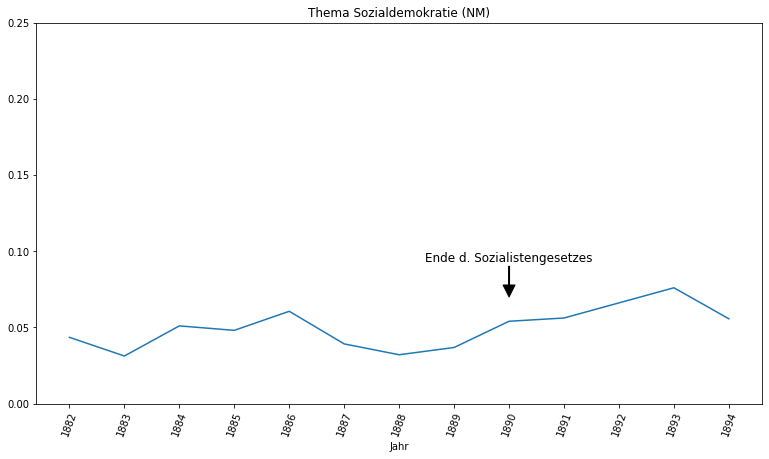
Anhand des Themas Sozialdemokratie ist der Aufschwung sozialistischer Strömungen im Kaiserreich ablesbar. Während in der Provinzial-Correspondenz das Thema eine untergeordnete Rolle spielt und Ausschläge nur im Rahmen besonderer Ereignisse, wie der Reichstagswahl 1874 und dem Sozialistengesetz 1878, festzustellen sind, behandeln die Neuesten Mittheilungen die Sozialdemokratie deutlich konstanter und prominenter, was sicherlich auch mit dem erheblichen Zugewinn an sozialistischen Abgeordneten im Reichstag ab 1890 zu erklären ist. Interessant ist auch die Beobachtung, dass das Ende des Sozialistengesetztes 1890 keinen wirklichen Ausschlag auslöste, sondern lediglich Teil der sowieso reichen Berichterstattung über die Sozialdemokratie in dieser Zeit war.
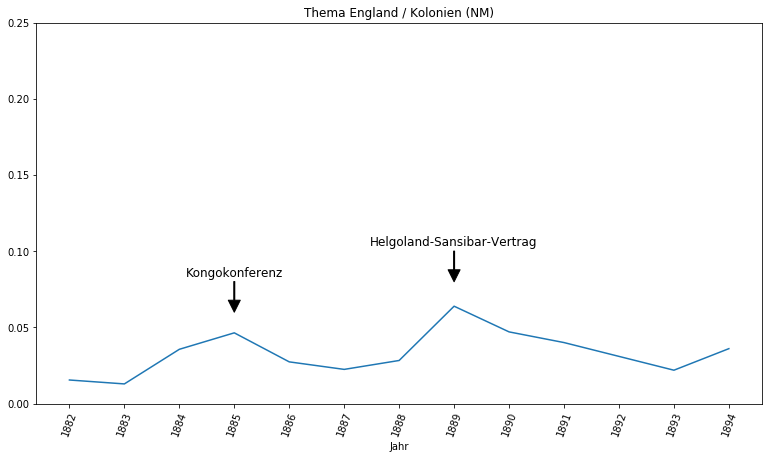
Das Topic Modeling Tool hat das Thema England und Kolonien zu einem Topic zusammengelegt, was die Verbindung der deutschen Kolonialgeschichte zur englischen verdeutlicht. Tatsächlich bilden die Kongokonferenz und der Helgoland-Sansibar-Vertrag die beiden Höhepunkte dieses Topics.
Diese Ausschläge können dabei stellenweise trivial erscheinen, denn wir kennen die deutsche Geschichte und wissen, dass der Ausschlag 1870 vermutlich mit dem Deutsch-Französischen Krieg zusammenhängt. Entscheidend sind aber gerade die Ausschläge, die uns überraschen und die wir nicht sofort einordnen können. Sie sind es, die uns dazu bringen, an dieser Stelle genauer nachzuforschen und die erkenntnisversprechenden Stellen im Korpus ausfindig zu machen, die wir durch reines Lesen erst nach sehr langer Zeit gefunden hätten. In diesem Sinne ist es die Kombination des Topics Modelings und der quantitativen Exploration, die einem Forscher erlaubt, mit Text Mining einen Überblick über einen für eine Einzelperson scheinbar undurchdringlich großen Textkorpus zu gewinnen, diesen zu charakterisieren, erste aussagekräftige Befunde zu machen, Hypothesen zu bilden und ihn auf relevante Stellen hinweist, so dass anschließend eine genauere qualitative Untersuchung stattfinden kann.